
Extracts editable text from images, PDFs, and handwriting with broad language support.

Product memo
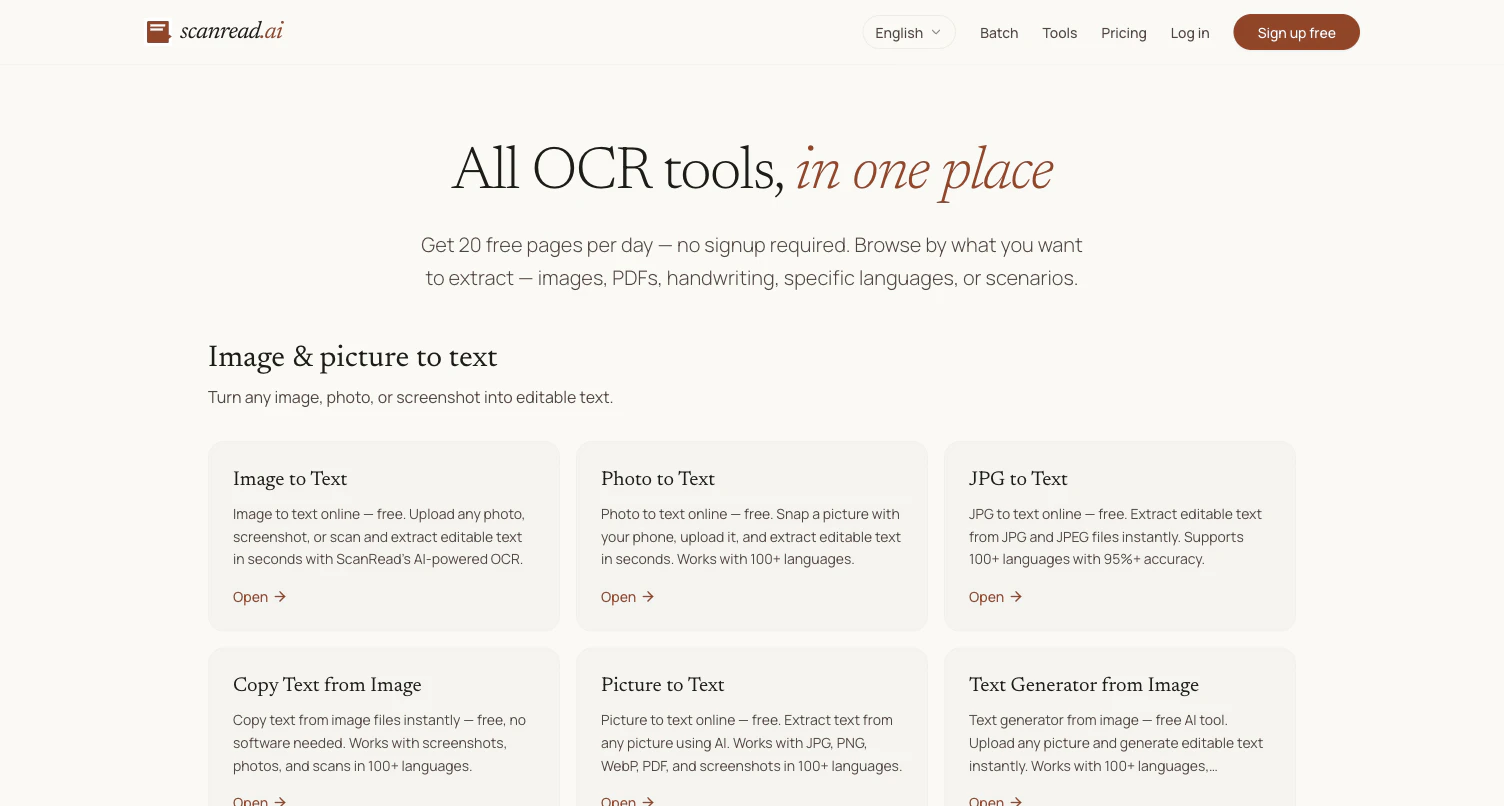
Users needing to convert images, documents, or even handwriting into editable text turn to ScanRead.ai. It handles screenshots, PDFs, and photos, offering a no-signup free tier to remove adoption friction. With support for over 100 languages, it serves a global audience looking to digitize notes or receipts quickly.
For who
Users needing to convert images/documents to editable text
Solves what
Extracts editable text from screenshots, PDFs, images, and handwriting.
- OCR text extraction
- Supports 100+ languages
- No signup required for basic use
In their own words
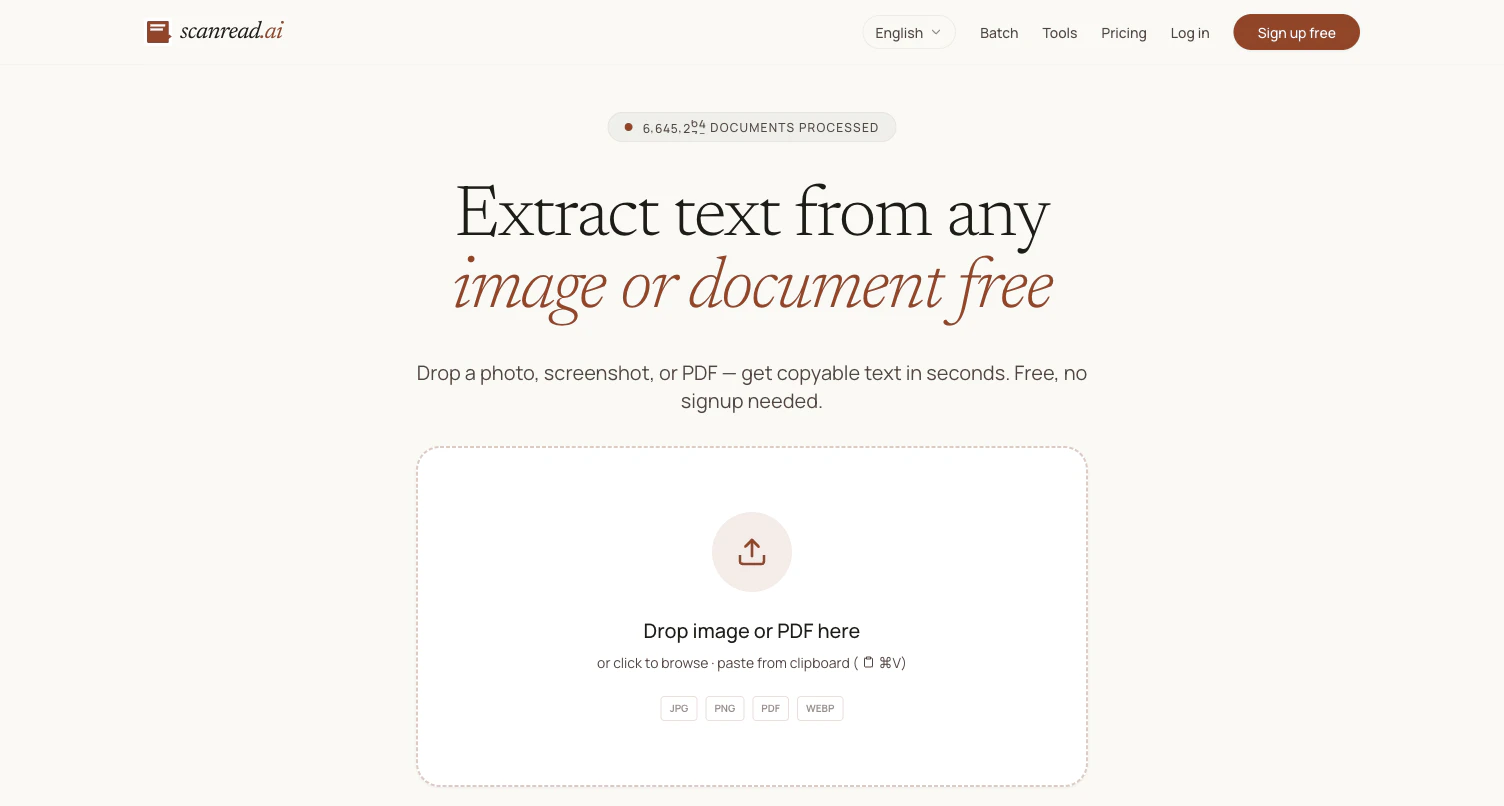
Extract text from any image or document free
Drop a photo, screenshot, or PDF — get copyable text in seconds. Free, no signup needed.
Commercial cues
Model
subscription
Free tier
Yes
Trial
No
Pricing Strategy
- • Free tier lowers testing friction.
- • Unlimited adds Unlimited pages.
Operator context
Operating setup
Founded
May 2026
Platform
Web app
Audience
General
Tech stack
Market demand
Scanread keyword demand
5 keywords
Market demand is Starter-tier market intelligence.
Derived from this product’s latest SimilarWeb keyword mix — directional demand, not proof.
Builder Strategy
- Strategy Type
- Niche Specialist
- Stage
- Pre Revenue
- Effort
- Solo Buildable
About Scanread Expand
ScanRead.ai provides OCR text extraction, allowing users to convert various visual sources into editable text. It targets anyone needing to digitize information quickly, from students to professionals.
The tool handles screenshots, PDFs, images, and even handwriting, supporting over 100 languages. Its positioning as an accessible, versatile product for everyday tasks, coupled with a no-signup free tier, lowers the barrier for new users.