
Toto
Routes LLM tasks to the cheapest model, cutting API spend for teams.


Product memo
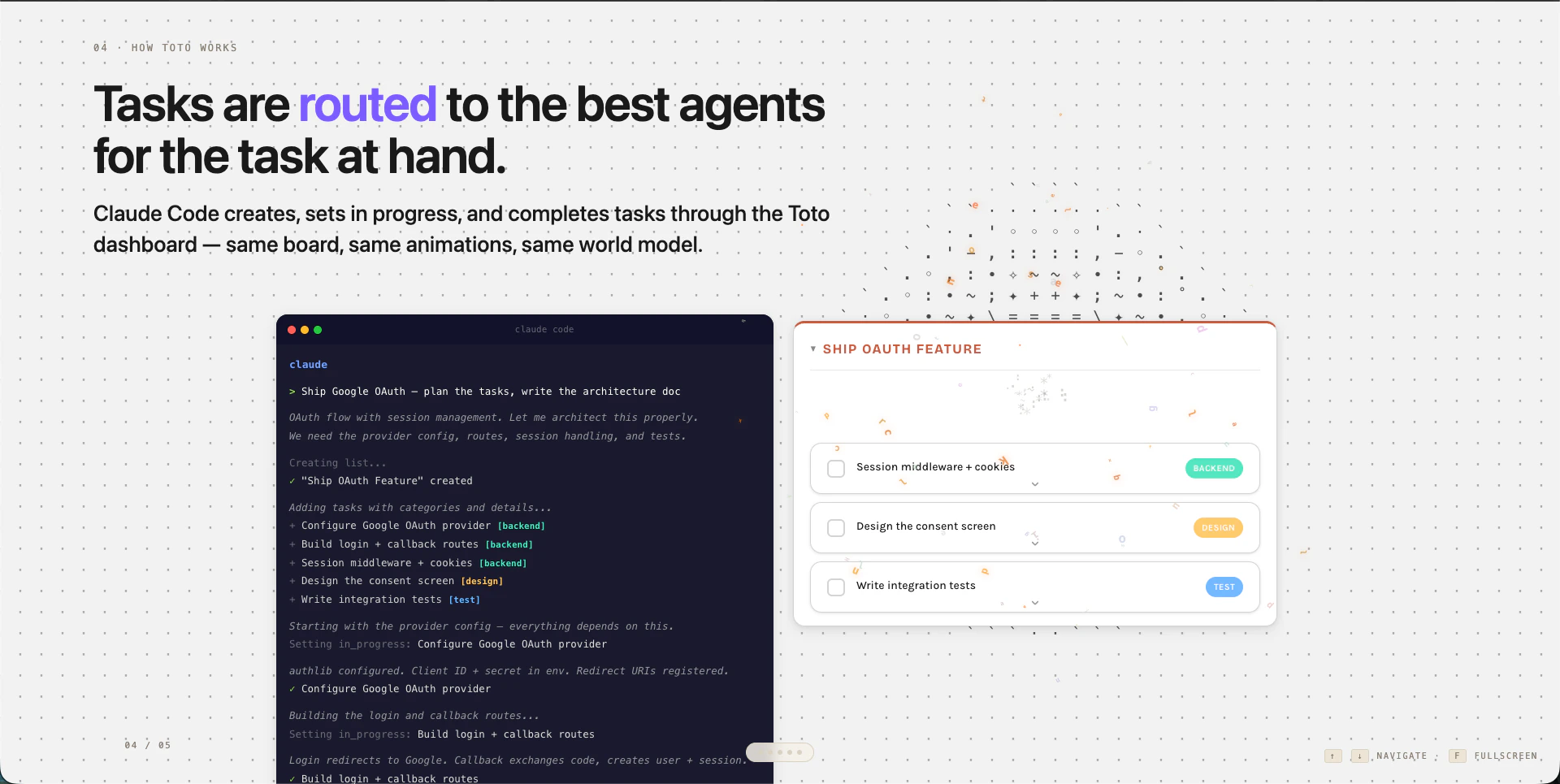
Teams overspending on large language model (LLM) calls use Toto to route tasks to the most cost-effective model. It acts as an interaction layer for human-agent workflows, optimizing prompt spend without sacrificing outcome quality. This positions the product as an essential AI infrastructure tool for managing LLM usage efficiently.
- For who
- Teams overspending on LLM calls
- Solves what
- Routes tasks to the cheapest capable LLM model
- Intelligent model routing
- Cost optimization
- Real-time state management
In their own words
You are spending too much on the wrong tokens.
Wrong model on the wrong task — every prompt, every day. Toto routes each task to the cheapest capable model. Same outcome at a fraction of the spend.
Operator & company
Company
- Founded
May 2026
- HQ
United States
Operating model
- Business model
Saas
- Platform
Web app
- Audience
Developers
Product channels
Builder strategy
- Strategy Type
- Niche Specialist
- Stage
- Pre Revenue
- Effort
- Solo Buildable
About Toto Expand
Toto provides a routing layer designed to optimize spending on large language model (LLM) API calls. It serves teams that find themselves overspending on LLM usage by intelligently directing tasks to the most cost-effective model available for each job.
This approach ensures that users achieve the same outcomes at a fraction of the original expense.
Niche context
LLM Optimization
8 tracked →Adjacent niches
Competitive context
5 peers · Same primary niche · Radar benchmark · Toto #5212.


Commercial cues
- Model
- subscription
- Free tier
- No
- Trial
- No
Pricing strategy
- • Before-and-after pricing clearly quantifies the potential savings.