
API for deterministic PDF normalization, ensuring canonical hashing and active content removal.



Product memo
Targets developers and security teams grappling with the inherent instability of PDF files, which often leads to audit failures and security vulnerabilities. Its wedge is deterministic normalization, ensuring identical logical documents always yield the same hash, a critical distinction from standard viewers. This provides a stable foundation for deduplication, digital signing, and compliance reporting where byte-for-byte consistency is paramount.
For who
Developers and security teams handling untrusted PDFs
Solves what
Normalizes PDFs for deterministic hashing and security by removing active content.
- Deterministic PDF normalization
- Canonical SHA-256 hashing
- JavaScript and active content removal
In their own words
PDFs that always hash the same
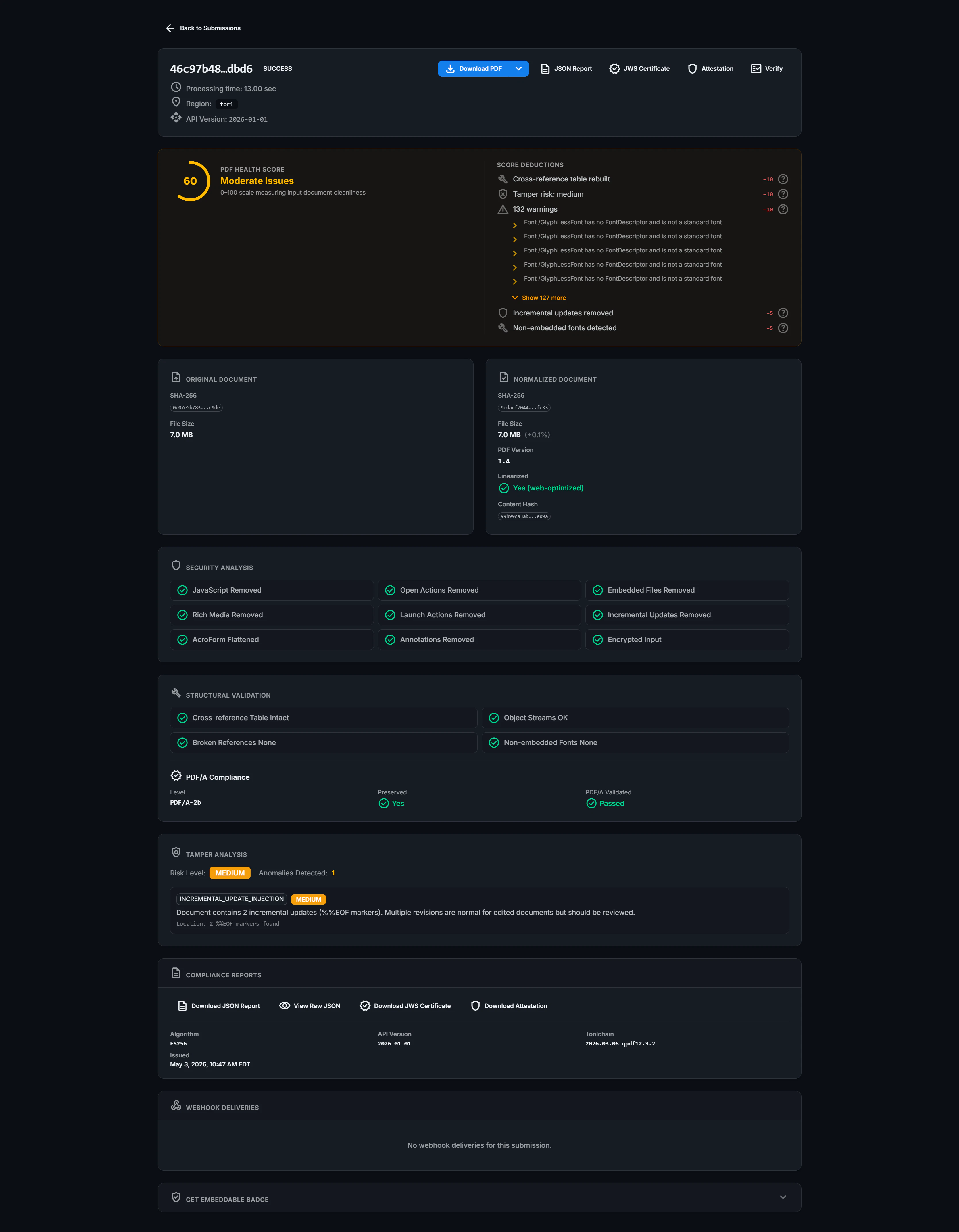
Two visually identical PDFs can still produce different SHA-256 hashes - hidden revisions, scripts, and metadata change with every save. PDFCanon strips all of it and rewrites the file deterministically, so the same logical document hashes to the same value, bit-for-bit, in any region, on any host.
Convert untrusted PDFs into structurally normalized, canonical documents with stable SHA-256 hashes and compliance-ready audit reports.
Commercial cues
Model
subscription
Free tier
Yes
Trial
Available
Free
Deterministic structural normalization
Starter
$83.16/mo billed annually
Deterministic structural normalization
Growth
$209.16/mo billed annually
Deterministic structural normalization
Pro
$419.16/mo billed annually
Deterministic structural normalization
Pricing Strategy
Employs a tiered subscription model based on monthly PDF processing volume, complemented by a generous free tier.
- • A generous free tier encourages adoption and frictionless API testing, lowering the barrier to entry.
- • Volume-based tiers scale directly with user needs, ensuring costs align with actual usage as demand grows.
- • An annual discount incentivizes longer-term commitment, securing predictable revenue and customer stickiness.
Operator context
Team
Indie / lean
Founded
May 2026
Tech stack
Social / footprint
Builder Strategy
- Strategy Type
- Niche Specialist
- Stage
- Bootstrapped Lean
- Effort
- Solo Buildable
Targets developers with a clear API-first wedge for PDF normalization, solving a niche but critical problem for audits and security.
Unfair Advantages
-
Proprietary Data Deterministic normalization algorithm is the core IP
-
Exclusive Distribution API-first approach with a free tier drives developer adoption
Builder Lesson
Focus on a single, critical technical problem and offer a free tier API to drive developer adoption.
Full Reasoning
Wins by owning the niche of deterministic PDF normalization, a problem most developers don't realize they have until verifiable document integrity becomes a painful necessity. The asymmetric bet is its API-first strategy, paired with a generous free tier, allowing developers to integrate and test without friction. Other builders: in mature markets, a deep technical solution to a specific, painful problem can be a strong wedge, especially when paired with a developer-friendly distribution model.
About PDFCanon Expand
PDFCanon offers a specialized API designed for developers and security teams who need to process untrusted PDF documents with absolute consistency. It tackles the often-overlooked problem of PDF instability, where minor, invisible changes can alter a file's hash, complicating security and compliance efforts.
The service normalizes PDFs by stripping out active content like JavaScript, eliminating incremental updates, and canonicalizing metadata. This process ensures that logically identical PDFs always produce the same SHA-256 hash, a critical feature for applications requiring verifiable document integrity, such as digital signing, deduplication, and audit trails.
PDFCanon stands out by providing a robust, API-first solution that simplifies a complex technical challenge, allowing teams to build more secure and compliant document workflows without deep PDF parsing expertise.