
Intelligent scraping API routing requests for cost-optimized web data extraction.
Product memo
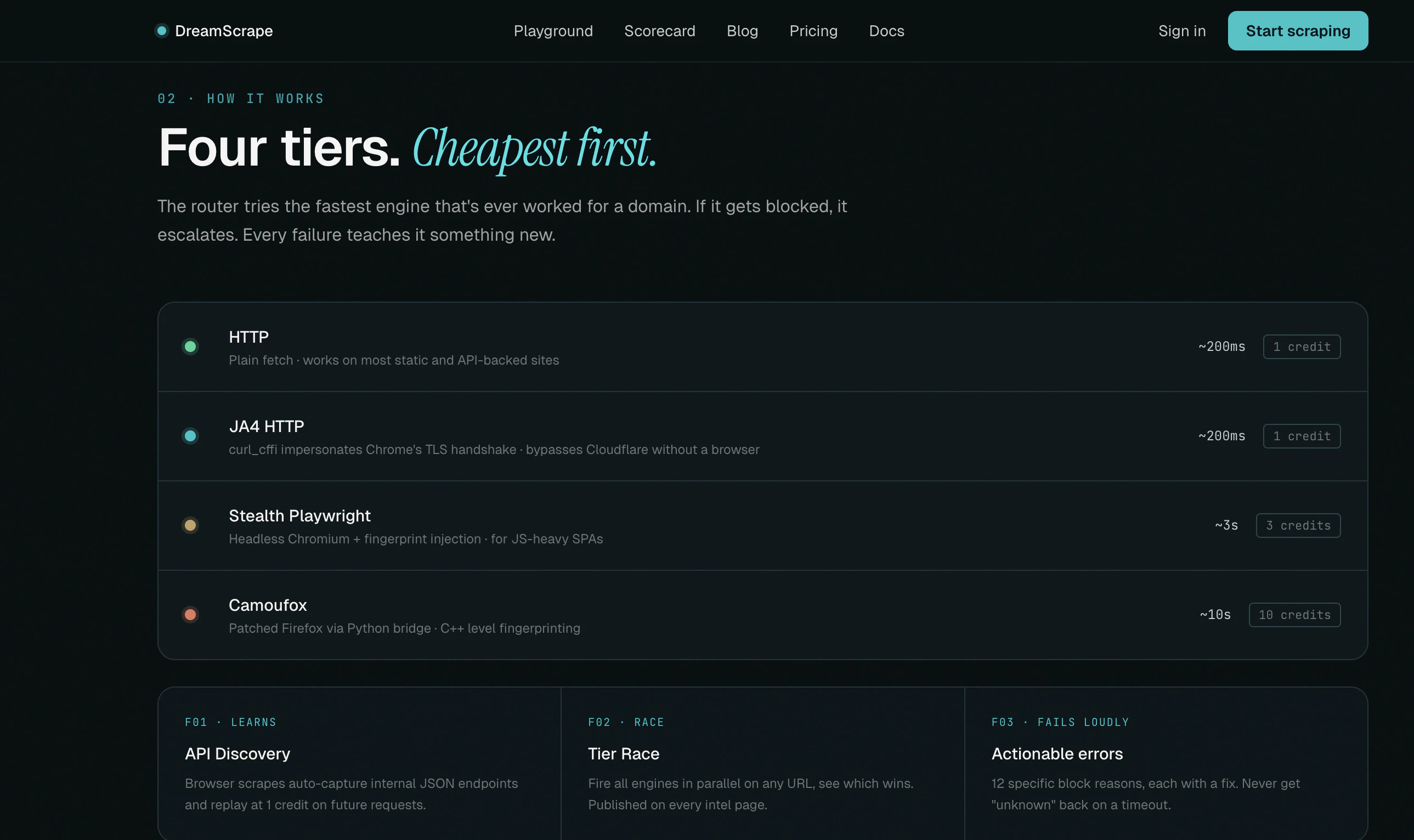
DreamScrape offers an automated web scraping API that cuts costs by dynamically picking the most efficient engine for each request. It routes through HTTP, JA4-fingerprinted HTTP, stealth browser, or anti-detect Firefox, learning from failures to optimize future scrapes. This approach targets developers and data engineers who need reliable extraction without overpaying for unnecessary complexity.
For who
Developers and data engineers needing efficient web scraping
Solves what
Automated, cost-optimized web scraping by intelligently routing requests.
- Smart engine routing
- Credit-based pricing
- API endpoint
In their own words
Your request finds the cheapest path.
DreamScrape routes every request through the tier that actually works — plain HTTP, JA4-fingerprinted HTTP, stealth browser, or anti-detect Firefox. You get clean markdown. It picks the engine.
Smart routing picks HTTP, stealth browser, or anti-detect Firefox per domain. Credit-based pricing — you pay for what you actually need.
Commercial cues
Model
usage_based
Free tier
No
Trial
No
Operator context
Founded
May 2026
Platform
API
Audience
Developers
Builder Strategy
- Strategy Type
- Niche Specialist
- Stage
- Pre Revenue
- Effort
- Small Team
About DreamScrape Expand
DreamScrape provides developers and data engineers with an automated web scraping API. It intelligently routes requests through various scraping engines, including HTTP, stealth browser, and anti-detect Firefox, to ensure cost-optimized data extraction.
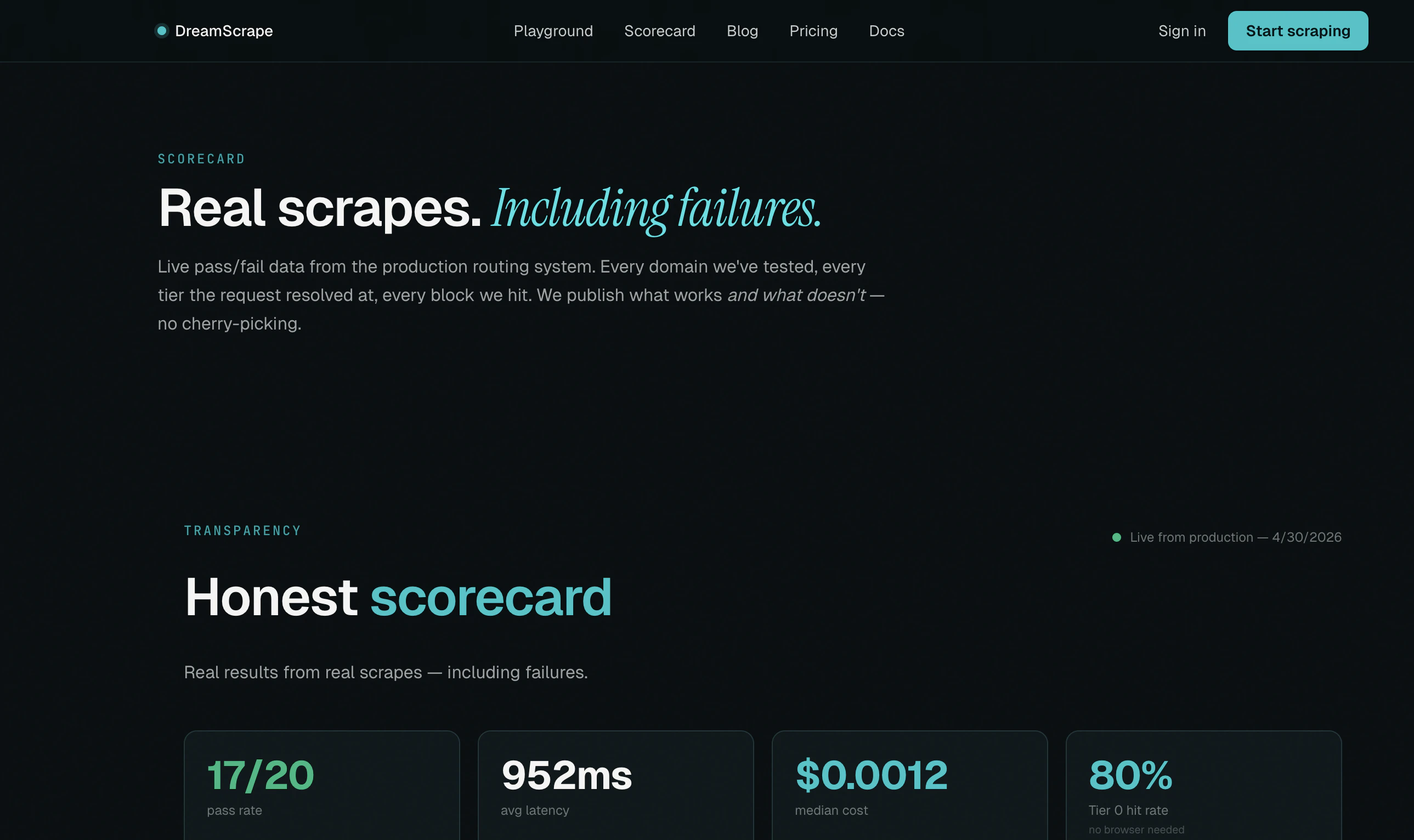
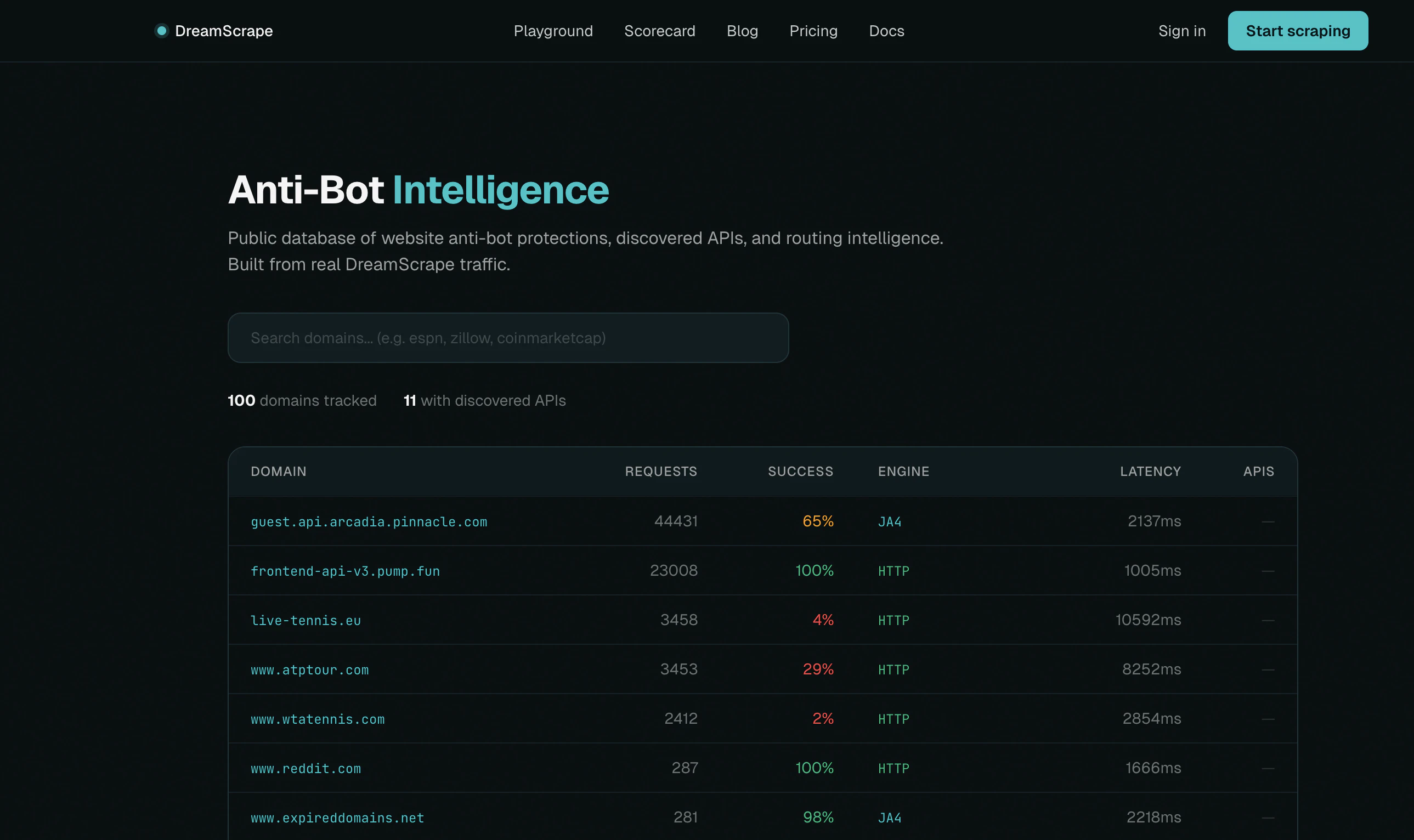
The service learns from past request failures to improve future scraping success rates. This focus on efficiency and cost makes DreamScrape a practical option for teams needing reliable web data without the overhead of managing complex scraping infrastructure or overpaying for unnecessary features.
Its API endpoint and credit-based pricing model simplify integration and cost management for high-volume data needs.