
Enforces LLM spending limits and optimizes token usage on your infrastructure.
Product memo
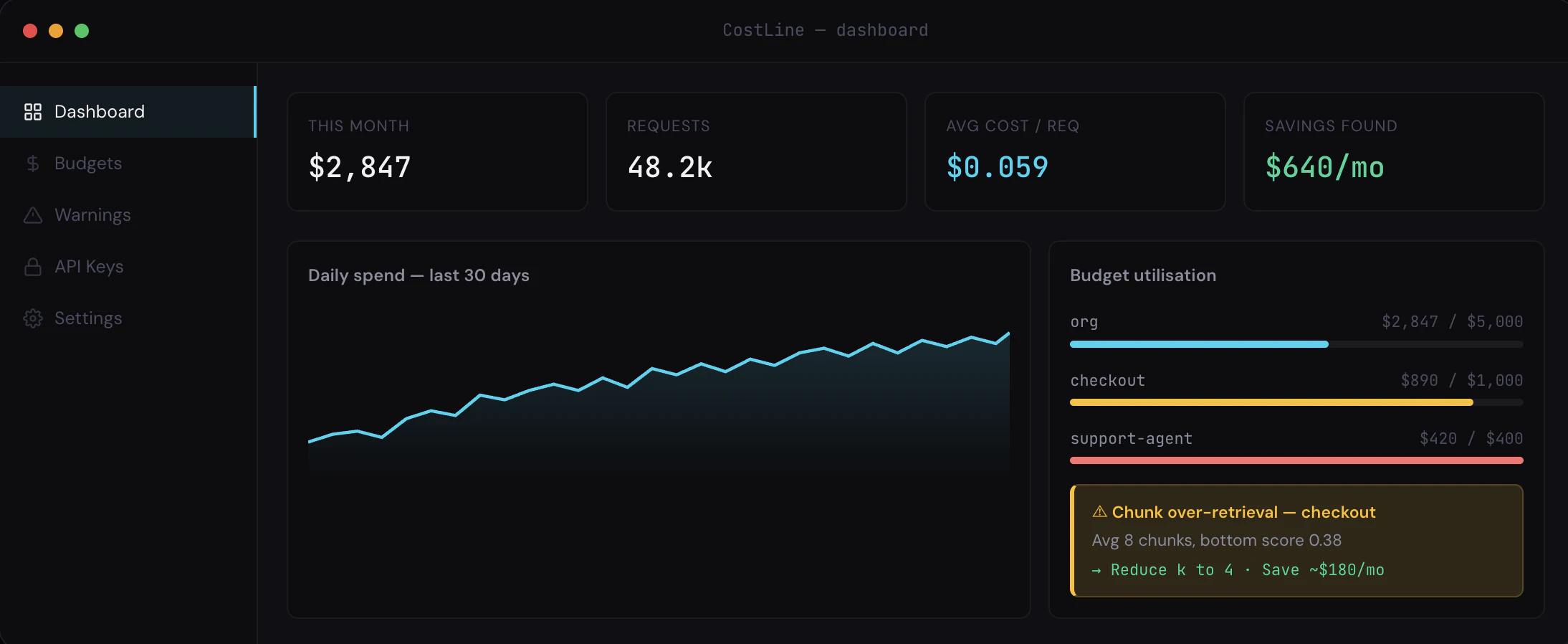
CostLine helps AI-native startups and engineering teams control LLM expenses. It enforces hard spending limits and offers token waste intelligence, all deployed directly on customer infrastructure. This approach addresses the critical need for cost predictability and data privacy in AI development, ensuring no data leaves the user's environment.
For who
AI-native startups and engineering teams
Solves what
Enforces LLM spending limits and optimizes token usage.
- Hard budget stops
- Token waste intelligence
- Self-hosted deployment
In their own words
Stop _guessing_ what
Hard spending limits that actually enforce. Intelligence that tells you exactly where tokens are wasted. Deploys entirely on your infrastructure.
Commercial cues
Model
subscription
Free tier
No
Trial
No
Operator context
Founded
May 2026
Platform
Web app
Audience
Developers
Social / footprint
Builder Strategy
- Strategy Type
- Niche Specialist
- Stage
- Vc Growth
- Effort
- Small Team
About CostLine Expand
CostLine provides critical LLM spend management for AI-native startups and engineering teams. It offers hard spending limits and token waste intelligence, helping users control costs and optimize large language model usage.
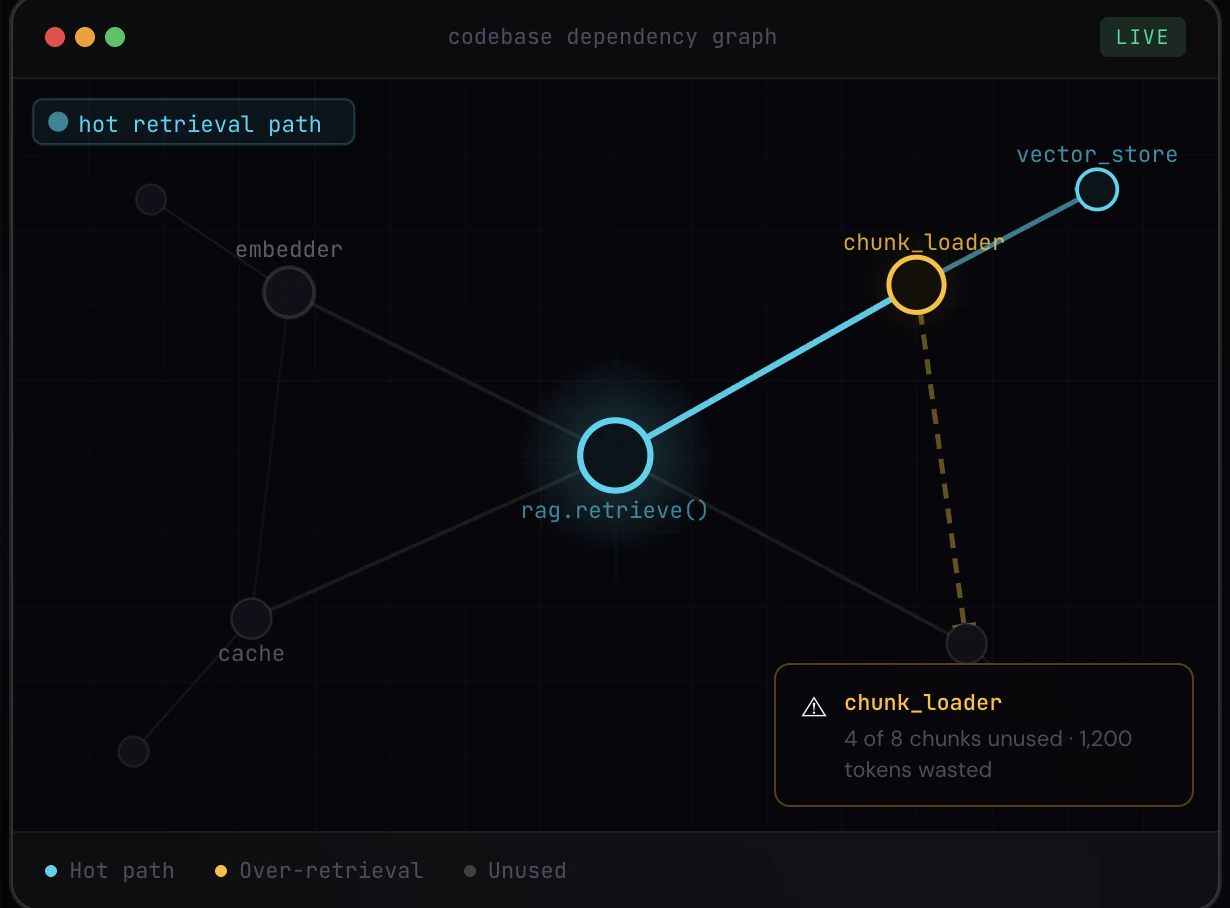
The product's core differentiator is its self-hosted deployment, running entirely on your infrastructure using Kubernetes or Docker. This approach ensures zero data leaves the user's environment, addressing significant data privacy and security concerns for companies working with sensitive AI models.
CostLine focuses on practical features like RAG over-retrieval detection and history bloat detection to deliver tangible cost savings.